注意
转至结尾 下载完整的示例代码。
3.4.8.11. 加州房价数据上的简单回归分析¶
这里我们对加州房价数据进行简单的回归分析,探索两种类型的回归器。
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing(as_frame=True)
打印要预测的数量的直方图:价格
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 3))
plt.hist(data.target)
plt.xlabel("price ($100k)")
plt.ylabel("count")
plt.tight_layout()

打印每个特征的联合直方图
for index, feature_name in enumerate(data.feature_names):
plt.figure(figsize=(4, 3))
plt.scatter(data.data[feature_name], data.target)
plt.ylabel("Price", size=15)
plt.xlabel(feature_name, size=15)
plt.tight_layout()
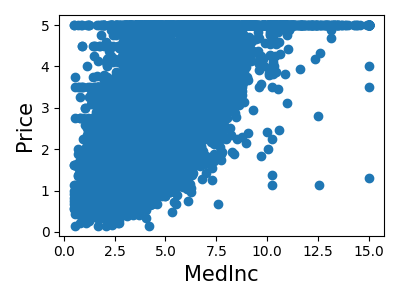
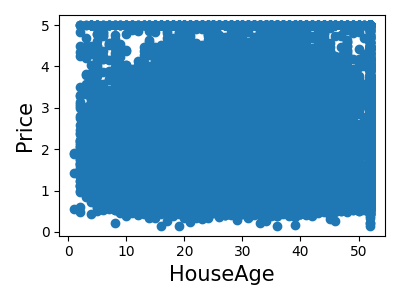
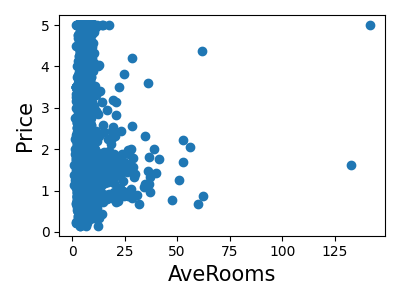
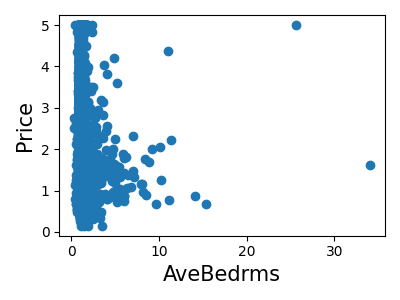
简单预测
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target)
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
clf.fit(X_train, y_train)
predicted = clf.predict(X_test)
expected = y_test
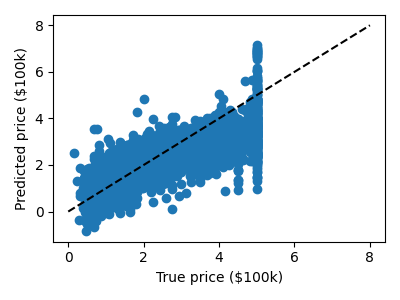
plt.figure(figsize=(4, 3))
plt.scatter(expected, predicted)
plt.plot([0, 8], [0, 8], "--k")
plt.axis("tight")
plt.xlabel("True price ($100k)")
plt.ylabel("Predicted price ($100k)")
plt.tight_layout()
使用梯度提升树预测
from sklearn.ensemble import GradientBoostingRegressor
clf = GradientBoostingRegressor()
clf.fit(X_train, y_train)
predicted = clf.predict(X_test)
expected = y_test
plt.figure(figsize=(4, 3))
plt.scatter(expected, predicted)
plt.plot([0, 5], [0, 5], "--k")
plt.axis("tight")
plt.xlabel("True price ($100k)")
plt.ylabel("Predicted price ($100k)")
plt.tight_layout()

打印错误率
RMS: np.float64(0.5314909993118918)
脚本总运行时间:(0 分钟 4.708 秒)