2.2. NumPy 进阶¶
作者: Pauli Virtanen
NumPy 是 Python 科学工具栈的基础。它的目的是在内存块中对许多项目进行高效操作。详细了解其工作原理有助于有效利用其灵活性,并采取有用的捷径。
本节涵盖
NumPy 数组的结构及其后果。技巧和窍门。
通用函数:是什么,为什么,以及如果你想要一个新的通用函数该怎么做。
与其他工具的集成:NumPy 提供了几种方法来包装任何数据到 ndarray 中,而无需不必要的复制。
最近添加的功能以及它们包含的内容:PEP 3118 缓冲区,广义 ufunc,…
提示
在本节中,NumPy 将按如下方式导入
>>> import numpy as np
2.2.1. ndarray 的生命周期¶
2.2.1.1. 它是…¶
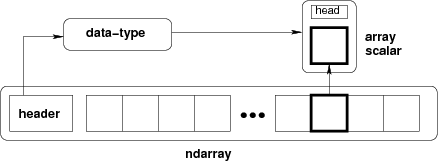
ndarray =
内存块 + 索引方案 + 数据类型描述符
原始数据
如何定位元素
如何解释元素
typedef struct PyArrayObject {
PyObject_HEAD
/* Block of memory */
char *data;
/* Data type descriptor */
PyArray_Descr *descr;
/* Indexing scheme */
int nd;
npy_intp *dimensions;
npy_intp *strides;
/* Other stuff */
PyObject *base;
int flags;
PyObject *weakreflist;
} PyArrayObject;
2.2.1.2. 内存块¶
>>> x = np.array([1, 2, 3], dtype=np.int32)
>>> x.data
<... at ...>
>>> bytes(x.data)
b'\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00'
数据的内存地址
>>> x.__array_interface__['data'][0]
64803824
整个 __array_interface__
>>> x.__array_interface__
{'data': (..., False), 'strides': None, 'descr': [('', '<i4')], 'typestr': '<i4', 'shape': (3,), 'version': 3}
提醒:两个 ndarrays 可能共享相同的内存
>>> x = np.array([1, 2, 3, 4])
>>> y = x[:-1]
>>> x[0] = 9
>>> y
array([9, 2, 3])
内存不需要由 ndarray 拥有
>>> x = b'1234'
x 是一个字符串(在 Python 3 中是字节),我们可以将其数据表示为整数数组
>>> y = np.frombuffer(x, dtype=np.int8)
>>> y.data
<... at ...>
>>> y.base is x
True
>>> y.flags
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : False
WRITEABLE : False
ALIGNED : True
WRITEBACKIFCOPY : False
owndata 和 writeable 标志指示内存块的状态。
另请参阅
2.2.1.3. 数据类型¶
描述符¶
dtype 描述数组中的单个项目
类型 |
数据的标量类型,以下之一 int8、int16、float64 等(固定大小) str、unicode、void(灵活大小) |
itemsize |
数据块的大小 |
byteorder |
字节序:大端 |
字段 |
子数据类型,如果它是结构化数据类型 |
形状 |
数组的形状,如果它是子数组 |
>>> np.dtype(int).type
<class 'numpy.int64'>
>>> np.dtype(int).itemsize
8
>>> np.dtype(int).byteorder
'='
示例:读取 .wav 文件¶
.wav 文件头
chunk_id |
|
chunk_size |
4 字节无符号小端整数 |
格式 |
|
fmt_id |
|
fmt_size |
4 字节无符号小端整数 |
audio_fmt |
2 字节无符号小端整数 |
num_channels |
2 字节无符号小端整数 |
sample_rate |
4 字节无符号小端整数 |
byte_rate |
4 字节无符号小端整数 |
block_align |
2 字节无符号小端整数 |
bits_per_sample |
2 字节无符号小端整数 |
data_id |
|
data_size |
4 字节无符号小端整数 |
44 字节的原始数据块(在文件开头)
… 后跟
data_size字节的实际声音数据。
作为 NumPy 结构化数据类型的 .wav 文件头
>>> wav_header_dtype = np.dtype([
... ("chunk_id", (bytes, 4)), # flexible-sized scalar type, item size 4
... ("chunk_size", "<u4"), # little-endian unsigned 32-bit integer
... ("format", "S4"), # 4-byte string
... ("fmt_id", "S4"),
... ("fmt_size", "<u4"),
... ("audio_fmt", "<u2"), #
... ("num_channels", "<u2"), # .. more of the same ...
... ("sample_rate", "<u4"), #
... ("byte_rate", "<u4"),
... ("block_align", "<u2"),
... ("bits_per_sample", "<u2"),
... ("data_id", ("S1", (2, 2))), # sub-array, just for fun!
... ("data_size", "u4"),
... #
... # the sound data itself cannot be represented here:
... # it does not have a fixed size
... ])
另请参阅
wavreader.py
>>> wav_header_dtype['format']
dtype('S4')
>>> wav_header_dtype.fields
mappingproxy({'chunk_id': (dtype('S4'), 0), 'chunk_size': (dtype('uint32'), 4), 'format': (dtype('S4'), 8), 'fmt_id': (dtype('S4'), 12), 'fmt_size': (dtype('uint32'), 16), 'audio_fmt': (dtype('uint16'), 20), 'num_channels': (dtype('uint16'), 22), 'sample_rate': (dtype('uint32'), 24), 'byte_rate': (dtype('uint32'), 28), 'block_align': (dtype('uint16'), 32), 'bits_per_sample': (dtype('uint16'), 34), 'data_id': (dtype(('S1', (2, 2))), 36), 'data_size': (dtype('uint32'), 40)})
>>> wav_header_dtype.fields['format']
(dtype('S4'), 8)
第一个元素是结构化数据中的子数据类型,对应于名称
format第二个元素是它相对于项目开头的偏移量(以字节为单位)
>>> f = open('data/test.wav', 'r')
>>> wav_header = np.fromfile(f, dtype=wav_header_dtype, count=1)
>>> f.close()
>>> print(wav_header)
[ ('RIFF', 17402L, 'WAVE', 'fmt ', 16L, 1, 1, 16000L, 32000L, 2, 16, [['d', 'a'], ['t', 'a']], 17366L)]
>>> wav_header['sample_rate']
array([16000], dtype=uint32)
让我们尝试访问子数组
>>> wav_header['data_id']
array([[['d', 'a'],
['t', 'a']]],
dtype='|S1')
>>> wav_header.shape
(1,)
>>> wav_header['data_id'].shape
(1, 2, 2)
访问子数组时,维度会添加到末尾!
注意
有一些现有的模块,如 wavfile、audiolab 等,用于加载声音数据…
转换和重新解释/视图¶
转换
在赋值时
在数组构建时
在算术运算时
等等。
以及手动:
.astype(dtype)
数据重新解释
手动:
.view(dtype)
转换¶
算术运算中的转换,简而言之
只有操作数的类型(而不是值!)才重要
选择能够安全表示两者的最大类型
在某些情况下,标量可能会“输给”数组
一般情况下,转换会复制数据
>>> x = np.array([1, 2, 3, 4], dtype=float) >>> x array([1., 2., 3., 4.]) >>> y = x.astype(np.int8) >>> y array([1, 2, 3, 4], dtype=int8) >>> y + 1 array([2, 3, 4, 5], dtype=int8) >>> y + 256 Traceback (most recent call last): File "<stdin>", line 1, in <module> OverflowError: Python integer 256 out of bounds for int8 >>> y + 256.0 array([257., 258., 259., 260.]) >>> y + np.array([256], dtype=np.int32) array([257, 258, 259, 260], dtype=int32)
在 setitem 中转换:数组的 dtype 在项目赋值时不会更改
>>> y[:] = y + 1.5 >>> y array([2, 3, 4, 5], dtype=int8)
注意
精确规则:请参阅 NumPy 文档
重新解释/查看¶
内存中的数据块(4 字节)
0x01||
0x02||
0x03||
0x044 个 uint8,或者,
4 个 int8,或者,
2 个 int16,或者,
1 个 int32,或者,
1 个 float32,或者,
…
如何从一个切换到另一个?
切换 dtype
>>> x = np.array([1, 2, 3, 4], dtype=np.uint8) >>> x.dtype = "<i2" >>> x array([ 513, 1027], dtype=int16) >>> 0x0201, 0x0403 (513, 1027)
0x01
0x02||
0x03
0x04注意
小端:最低有效字节在内存中位于左侧
创建类型为
uint32的新视图,简写为i4>>> y = x.view("<i4") >>> y array([67305985], dtype=int32) >>> 0x04030201 67305985
0x01
0x02
0x03
0x04
注意
.view()创建视图,不会复制(或更改)内存块仅更改 dtype(并调整数组形状)
>>> x[1] = 5 >>> y array([328193], dtype=int32) >>> y.base is x True
小型练习:数据重新解释
另请参阅
view-colors.py
您在数组中拥有 RGBA 数据
>>> x = np.zeros((10, 10, 4), dtype=np.int8)
>>> x[:, :, 0] = 1
>>> x[:, :, 1] = 2
>>> x[:, :, 2] = 3
>>> x[:, :, 3] = 4
其中最后三个维度是 R、B 和 G 以及 alpha 通道。
如何在不复制数据的情况下创建一个具有字段名称“r”、“g”、“b”、“a”的 (10, 10) 结构化数组?
>>> y = ...
>>> assert (y['r'] == 1).all()
>>> assert (y['g'] == 2).all()
>>> assert (y['b'] == 3).all()
>>> assert (y['a'] == 4).all()
解答
警告
另外两个数组,每个数组占用正好 4 个字节的内存
>>> x = np.array([[1, 3], [2, 4]], dtype=np.uint8)
>>> x
array([[1, 3],
[2, 4]], dtype=uint8)
>>> y = x.transpose()
>>> y
array([[1, 2],
[3, 4]], dtype=uint8)
我们将 x 的元素(每个 1 字节)视为 int16(每个 2 字节)
>>> x.view(np.int16)
array([[ 769],
[1026]], dtype=int16)
这里发生了什么?查看 x 在内存中存储的字节
>>> x.tobytes()
b'\x01\x03\x02\x04'
\x 代表十六进制,所以我们看到的是
0x01 0x03 0x02 0x04
我们要求 NumPy 将这些字节解释为 dtype int16 的元素,每个元素在内存中占用两个字节。因此,0x01 0x03 成为第一个 uint16,而 0x02 0x04 成为第二个。
然后您可能会期望看到 0x0103(从十六进制转换为十进制为 259)作为第一个结果。但是您的计算机可能首先存储最高有效字节,因此将数字读取为 0x0301 或 769(继续在您的 Python 终端中键入 0x0301 以进行验证)。
我们可以在 y 的副本上执行相同的操作(为什么它不能直接在 y 上工作?)
>>> y.copy().view(np.int16)
array([[ 513],
[1027]], dtype=int16)
您可以解释这些数字 513 和 1027 以及结果数组的输出形状吗?
2.2.1.4. 索引方案:步长¶
要点¶
问题:
>>> x = np.array([[1, 2, 3],
... [4, 5, 6],
... [7, 8, 9]], dtype=np.int8)
>>> x.tobytes('A')
b'\x01\x02\x03\x04\x05\x06\x07\x08\t'
At which byte in ``x.data`` does the item ``x[1, 2]`` begin?
答案(在 NumPy 中)
步长 (strides):找到下一个元素需要跳过的字节数
每个维度 1 个步长
>>> x.strides
(3, 1)
>>> byte_offset = 3 * 1 + 1 * 2 # to find x[1, 2]
>>> x.flat[byte_offset]
np.int8(6)
>>> x[1, 2]
np.int8(6)
简单,灵活
C 顺序和 Fortran 顺序¶
注意
Python 内置的 bytes 默认情况下以 C 顺序返回字节,这在尝试检查内存布局时可能会造成混淆。我们使用 numpy.ndarray.tobytes() 并设置 order=A,这会保留内存中字节的 C 或 F 顺序。
>>> x = np.array([[1, 2, 3],
... [4, 5, 6]], dtype=np.int16, order='C')
>>> x.strides
(6, 2)
>>> x.tobytes('A')
b'\x01\x00\x02\x00\x03\x00\x04\x00\x05\x00\x06\x00'
需要跳过 6 个字节才能找到下一行
需要跳过 2 个字节才能找到下一列
>>> y = np.array(x, order='F')
>>> y.strides
(2, 4)
>>> y.tobytes('A')
b'\x01\x00\x04\x00\x02\x00\x05\x00\x03\x00\x06\x00'
需要跳过 2 个字节才能找到下一行
需要跳过 4 个字节才能找到下一列
更高维度的情况类似
C 顺序:最后几个维度变化最快(= 步长较小)
F 顺序:最前面的维度变化最快
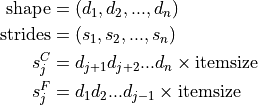
注意
现在我们可以理解 .view() 的行为
>>> y = np.array([[1, 3], [2, 4]], dtype=np.uint8).transpose()
>>> x = y.copy()
转置不会影响数据的内存布局,只会影响步长
>>> x.strides
(2, 1)
>>> y.strides
(1, 2)
>>> x.tobytes('A')
b'\x01\x02\x03\x04'
>>> y.tobytes('A')
b'\x01\x03\x02\x04'
当解释为 2 个 int16 时,结果不同
.copy()会创建新的数组,默认情况下按 C 顺序排列
注意
使用视图进行就地操作
在 NumPy 1.13 版本之前,对于大型数组,使用视图进行就地操作可能会导致错误的结果。从 1.13 版本 开始,NumPy 包含了对内存重叠的检查,以确保结果与非就地版本一致(例如,a = a + a.T 与 a += a.T 的结果相同)。但是请注意,这可能会导致数据被复制(就像使用 a += a.T.copy() 一样),最终导致使用的内存比就地操作预期要多!
使用整数进行切片¶
所有操作都可以通过仅更改
shape、strides以及可能调整data指针来表示!从不复制数据
>>> x = np.array([1, 2, 3, 4, 5, 6], dtype=np.int32)
>>> y = x[::-1]
>>> y
array([6, 5, 4, 3, 2, 1], dtype=int32)
>>> y.strides
(-4,)
>>> y = x[2:]
>>> y.__array_interface__['data'][0] - x.__array_interface__['data'][0]
8
>>> x = np.zeros((10, 10, 10), dtype=float)
>>> x.strides
(800, 80, 8)
>>> x[::2,::3,::4].strides
(1600, 240, 32)
类似地,转置从不复制数据(它只是交换步长)
>>> x = np.zeros((10, 10, 10), dtype=float) >>> x.strides (800, 80, 8) >>> x.T.strides (8, 80, 800)
但是:并非所有重塑操作都可以通过操作步长来表示
>>> a = np.arange(6, dtype=np.int8).reshape(3, 2)
>>> b = a.T
>>> b.strides
(1, 2)
到目前为止,一切顺利。然而
>>> bytes(a.data)
b'\x00\x01\x02\x03\x04\x05'
>>> b
array([[0, 2, 4],
[1, 3, 5]], dtype=int8)
>>> c = b.reshape(3*2)
>>> c
array([0, 2, 4, 1, 3, 5], dtype=int8)
这里,无法使用一个步长和 a 的内存块来表示数组 c。因此,reshape 操作需要在此处进行复制。
示例:使用步长伪造维度¶
步长操作
>>> from numpy.lib.stride_tricks import as_strided
>>> help(as_strided)
Help on function as_strided in module numpy.lib.stride_tricks:
...
警告
as_strided 不会检查您是否保持在内存块边界内……
>>> x = np.array([1, 2, 3, 4], dtype=np.int16)
>>> as_strided(x, strides=(2*2, ), shape=(2, ))
array([1, 3], dtype=int16)
>>> x[::2]
array([1, 3], dtype=int16)
另请参阅
stride-fakedims.py
练习
array([1, 2, 3, 4], dtype=np.int8) -> array([[1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]], dtype=np.int8)仅使用
as_strided。Hint: byte_offset = stride[0]*index[0] + stride[1]*index[1] + ...
剧透
广播¶
用它做一些有用的事情:
[1, 2, 3, 4]和[5, 6, 7]的外积
>>> x = np.array([1, 2, 3, 4], dtype=np.int16)
>>> x2 = as_strided(x, strides=(0, 1*2), shape=(3, 4))
>>> x2
array([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]], dtype=int16)
>>> y = np.array([5, 6, 7], dtype=np.int16)
>>> y2 = as_strided(y, strides=(1*2, 0), shape=(3, 4))
>>> y2
array([[5, 5, 5, 5],
[6, 6, 6, 6],
[7, 7, 7, 7]], dtype=int16)
>>> x2 * y2
array([[ 5, 10, 15, 20],
[ 6, 12, 18, 24],
[ 7, 14, 21, 28]], dtype=int16)
……似乎有点熟悉……
>>> x = np.array([1, 2, 3, 4], dtype=np.int16)
>>> y = np.array([5, 6, 7], dtype=np.int16)
>>> x[np.newaxis,:] * y[:,np.newaxis]
array([[ 5, 10, 15, 20],
[ 6, 12, 18, 24],
[ 7, 14, 21, 28]], dtype=int16)
在内部,数组广播确实使用 0 步长来实现。
更多技巧:对角线¶
另请参阅
stride-diagonals.py
挑战
选择矩阵的对角线元素:(假设 C 顺序内存)
>>> x = np.array([[1, 2, 3], ... [4, 5, 6], ... [7, 8, 9]], dtype=np.int32) >>> x_diag = as_strided(x, shape=(3,), strides=(???,))选择第一个超对角线元素
[2, 6]。以及次对角线元素?
- (最后两个的提示:切片首先移动步长
开始的位置。)
解答
另请参阅
stride-diagonals.py
挑战
计算张量的迹
>>> x = np.arange(5*5*5*5).reshape(5, 5, 5, 5) >>> s = 0 >>> for i in range(5): ... for j in range(5): ... s += x[j, i, j, i]通过步长,并对结果使用
sum()。>>> y = as_strided(x, shape=(5, 5), strides=(TODO, TODO)) >>> s2 = ... >>> assert s == s2
解答
CPU 缓存效应¶
内存布局会影响性能
In [1]: x = np.zeros((20000,))
In [2]: y = np.zeros((20000*67,))[::67]
In [3]: x.shape, y.shape
Out[3]: ((20000,), (20000,))
In [4]: %timeit x.sum()
5.29 us +- 6.06 ns per loop (mean +- std. dev. of 7 runs, 100,000 loops each)
In [5]: %timeit y.sum()
21.9 us +- 43.5 ns per loop (mean +- std. dev. of 7 runs, 10,000 loops each)
In [6]: x.strides, y.strides
Out[6]: ((8,), (536,))
步长越小越快?
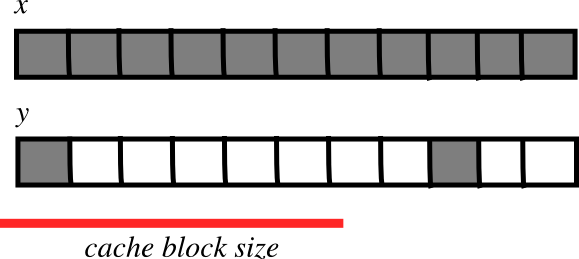
CPU 以块的形式将数据从主内存拉到其缓存中
如果许多连续操作的数组项适合一个块(步长小)
 需要更少的传输次数
需要更少的传输次数- 更快
2.2.1.5. 剖析中的发现¶
内存块:可以共享,
.base,.data数据类型描述符:结构化数据、子数组、字节序、转换、查看、
.astype()、.view()步长索引:步长、C/F 顺序、整数切片、
as_strided、广播、步长技巧、diag、CPU 缓存一致性
2.2.2. 通用函数¶
2.2.2.1. 它们是什么?¶
ufunc 对数组的所有元素执行逐元素操作。
示例
np.add, np.subtract, scipy.special.*, ...
自动支持:广播、转换……
ufunc 的作者只需要提供逐元素操作,NumPy 会处理其余部分。
逐元素操作需要用 C(或例如 Cython)实现
ufunc 的组成部分¶
用户提供
void ufunc_loop(void **args, int *dimensions, int *steps, void *data) { /* * int8 output = elementwise_function(int8 input_1, int8 input_2) * * This function must compute the ufunc for many values at once, * in the way shown below. */ char *input_1 = (char*)args[0]; char *input_2 = (char*)args[1]; char *output = (char*)args[2]; int i; for (i = 0; i < dimensions[0]; ++i) { *output = elementwise_function(*input_1, *input_2); input_1 += steps[0]; input_2 += steps[1]; output += steps[2]; } }
NumPy 部分,由
char types[3] types[0] = NPY_BYTE /* type of first input arg */ types[1] = NPY_BYTE /* type of second input arg */ types[2] = NPY_BYTE /* type of third input arg */ PyObject *python_ufunc = PyUFunc_FromFuncAndData( ufunc_loop, NULL, types, 1, /* ntypes */ 2, /* num_inputs */ 1, /* num_outputs */ identity_element, name, docstring, unused)
ufunc 还可以支持多种不同的输入输出类型组合。
简化操作¶
ufunc_loop形式非常通用,NumPy 提供了预制版本PyUfunc_f_ffloat elementwise_func(float input_1)PyUfunc_ff_ffloat elementwise_func(float input_1, float input_2)PyUfunc_d_ddouble elementwise_func(double input_1)PyUfunc_dd_ddouble elementwise_func(double input_1, double input_2)PyUfunc_D_Delementwise_func(npy_cdouble *input, npy_cdouble* output)PyUfunc_DD_Delementwise_func(npy_cdouble *in1, npy_cdouble *in2, npy_cdouble* out)只需要提供
elementwise_func……除非您的逐元素函数不属于上述形式之一
2.2.2.2. 练习:从头构建 ufunc¶
曼德勃罗集由以下迭代定义
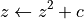
其中 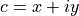 是一个复数。此迭代重复进行——如果
是一个复数。此迭代重复进行——如果  无论迭代运行多久都保持有限,则
无论迭代运行多久都保持有限,则  属于曼德勃罗集。
属于曼德勃罗集。
创建一个名为
mandel(z0, c)的 ufunc,它计算z = z0 for k in range(iterations): z = z*z + c
例如,100 次迭代或直到
z.real**2 + z.imag**2 > 1000。用它来确定哪些 c 位于曼德勃罗集中。我们的函数很简单,因此请使用
PyUFunc_*帮助程序。用 Cython 编写
另请参阅
mandel.pyx、mandelplot.py
提醒:一些预制 Ufunc 循环
|
|
|
|
|
|
|
|
|
|
|
|
类型代码
NPY_BOOL, NPY_BYTE, NPY_UBYTE, NPY_SHORT, NPY_USHORT, NPY_INT, NPY_UINT,
NPY_LONG, NPY_ULONG, NPY_LONGLONG, NPY_ULONGLONG, NPY_FLOAT, NPY_DOUBLE,
NPY_LONGDOUBLE, NPY_CFLOAT, NPY_CDOUBLE, NPY_CLONGDOUBLE, NPY_DATETIME,
NPY_TIMEDELTA, NPY_OBJECT, NPY_STRING, NPY_UNICODE, NPY_VOID
2.2.2.3. 解决方案:从头构建 ufunc¶
# The elementwise function
# ------------------------
cdef void mandel_single_point(double complex *z_in,
double complex *c_in,
double complex *z_out) noexcept nogil:
#
# The Mandelbrot iteration
#
#
# Some points of note:
#
# - It's *NOT* allowed to call any Python functions here.
#
# The Ufunc loop runs with the Python Global Interpreter Lock released.
# Hence, the ``nogil``.
#
# - And so all local variables must be declared with ``cdef``
#
# - Note also that this function receives *pointers* to the data;
# the "traditional" solution to passing complex variables around
#
cdef double complex z = z_in[0]
cdef double complex c = c_in[0]
cdef int k # the integer we use in the for loop
# Straightforward iteration
for k in range(100):
z = z*z + c
if z.real**2 + z.imag**2 > 1000:
break
# Return the answer for this point
z_out[0] = z
# Boilerplate Cython definitions
#
# Pulls definitions from the NumPy C headers.
# -------------------------------------------
from numpy cimport import_array, import_ufunc
from numpy cimport (PyUFunc_FromFuncAndData,
PyUFuncGenericFunction)
from numpy cimport NPY_CDOUBLE
from numpy cimport PyUFunc_DD_D
# Required module initialization
# ------------------------------
import_array()
import_ufunc()
# The actual ufunc declaration
# ----------------------------
cdef PyUFuncGenericFunction loop_func[1]
cdef char input_output_types[3]
cdef void *elementwise_funcs[1]
loop_func[0] = PyUFunc_DD_D
input_output_types[0] = NPY_CDOUBLE
input_output_types[1] = NPY_CDOUBLE
input_output_types[2] = NPY_CDOUBLE
elementwise_funcs[0] = <void*>mandel_single_point
mandel = PyUFunc_FromFuncAndData(
loop_func,
elementwise_funcs,
input_output_types,
1, # number of supported input types
2, # number of input args
1, # number of output args
0, # `identity` element, never mind this
"mandel", # function name
"mandel(z, c) -> computes iterated z*z + c", # docstring
0 # unused
)
"""
Plot Mandelbrot
================
Plot the Mandelbrot ensemble.
"""
import numpy as np
import mandel
x = np.linspace(-1.7, 0.6, 1000)
y = np.linspace(-1.4, 1.4, 1000)
c = x[None, :] + 1j * y[:, None]
z = mandel.mandel(c, c)
import matplotlib.pyplot as plt
plt.imshow(abs(z) ** 2 < 1000, extent=[-1.7, 0.6, -1.4, 1.4])
plt.gray()
plt.show()
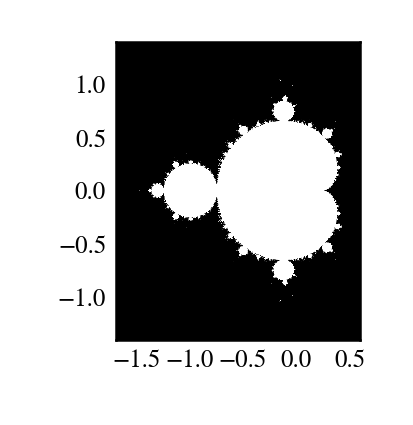
多个可接受的输入类型
例如,支持单精度和双精度版本
cdef void mandel_single_point(double complex *z_in,
double complex *c_in,
double complex *z_out) nogil:
...
cdef void mandel_single_point_singleprec(float complex *z_in,
float complex *c_in,
float complex *z_out) nogil:
...
cdef PyUFuncGenericFunction loop_funcs[2]
cdef char input_output_types[3*2]
cdef void *elementwise_funcs[1*2]
loop_funcs[0] = PyUFunc_DD_D
input_output_types[0] = NPY_CDOUBLE
input_output_types[1] = NPY_CDOUBLE
input_output_types[2] = NPY_CDOUBLE
elementwise_funcs[0] = <void*>mandel_single_point
loop_funcs[1] = PyUFunc_FF_F
input_output_types[3] = NPY_CFLOAT
input_output_types[4] = NPY_CFLOAT
input_output_types[5] = NPY_CFLOAT
elementwise_funcs[1] = <void*>mandel_single_point_singleprec
mandel = PyUFunc_FromFuncAndData(
loop_func,
elementwise_funcs,
input_output_types,
2, # number of supported input types <----------------
2, # number of input args
1, # number of output args
0, # `identity` element, never mind this
"mandel", # function name
"mandel(z, c) -> computes iterated z*z + c", # docstring
0 # unused
)
2.2.2.4. 广义 ufunc¶
ufunc
output = elementwise_function(input)
output和input都可以是单个数组元素。
广义 ufunc
output和input可以是具有固定维数的数组例如,矩阵迹(对角线元素之和)
input shape = (n, n) output shape = () i.e. scalar (n, n) -> ()矩阵乘积
input_1 shape = (m, n) input_2 shape = (n, p) output shape = (m, p) (m, n), (n, p) -> (m, p)
这称为广义 ufunc 的“签名”
广义 ufunc 作用的维度称为“核心维度”
NumPy 中的状态
NumPy 中已经存在广义 ufunc……
可以使用
PyUFunc_FromFuncAndDataAndSignature创建新的广义 ufunc大多数线性代数函数都实现为广义 ufunc,以支持处理堆叠数组
>>> import numpy as np >>> rng = np.random.default_rng(27446968) >>> np.linalg.det(rng.random((3, 5, 5))) array([ 0.01829761, -0.0077266 , -0.05336566]) >>> np.linalg._umath_linalg.det.signature '(m,m)->()'
以这种方式进行矩阵乘法对于同时操作许多小矩阵很有用
另请参阅
tensordot和einsum
广义 ufunc 循环
矩阵乘法 (m,n),(n,p) -> (m,p)
void gufunc_loop(void **args, int *dimensions, int *steps, void *data)
{
char *input_1 = (char*)args[0]; /* these are as previously */
char *input_2 = (char*)args[1];
char *output = (char*)args[2];
int input_1_stride_m = steps[3]; /* strides for the core dimensions */
int input_1_stride_n = steps[4]; /* are added after the non-core */
int input_2_strides_n = steps[5]; /* steps */
int input_2_strides_p = steps[6];
int output_strides_n = steps[7];
int output_strides_p = steps[8];
int m = dimension[1]; /* core dimensions are added after */
int n = dimension[2]; /* the main dimension; order as in */
int p = dimension[3]; /* signature */
int i;
for (i = 0; i < dimensions[0]; ++i) {
matmul_for_strided_matrices(input_1, input_2, output,
strides for each array...);
input_1 += steps[0];
input_2 += steps[1];
output += steps[2];
}
}
2.2.3. 互操作性特性¶
2.2.3.2. 旧的缓冲区协议¶
仅支持一维缓冲区
没有数据类型信息
C 级别接口;类型对象中的
PyBufferProcs tp_as_buffer但它已集成到 Python 中(例如,字符串支持它)
使用 Pillow(Python 图像库)进行的迷你练习
另请参阅
pilbuffer.py
>>> from PIL import Image
>>> data = np.zeros((200, 200, 4), dtype=np.uint8)
>>> data[:, :] = [255, 0, 0, 255] # Red
>>> # In PIL, RGBA images consist of 32-bit integers whose bytes are [RR,GG,BB,AA]
>>> data = data.view(np.int32).squeeze()
>>> img = Image.frombuffer("RGBA", (200, 200), data, "raw", "RGBA", 0, 1)
>>> img.save('test.png')
问题
检查如果现在修改了
data,然后再次保存img会发生什么。
2.2.3.3. 旧的缓冲区协议¶
"""
From buffer
============
Show how to exchange data between numpy and a library that only knows
the buffer interface.
"""
import numpy as np
from PIL import Image
# Let's make a sample image, RGBA format
x = np.zeros((200, 200, 4), dtype=np.uint8)
x[:, :, 0] = 255 # red
x[:, :, 3] = 255 # opaque
data = x.view(np.int32) # Check that you understand why this is OK!
img = Image.frombuffer("RGBA", (200, 200), data)
img.save("test.png")
# Modify the original data, and save again.
x[:, :, 1] = 255
img.save("test2.png")


2.2.3.4. 数组接口协议¶
多维缓冲区
存在数据类型信息
NumPy 特定的方法;正在逐渐弃用(但不会消失)
否则未集成到 Python 中
>>> x = np.array([[1, 2], [3, 4]])
>>> x.__array_interface__
{'data': (171694552, False), # memory address of data, is readonly?
'descr': [('', '<i4')], # data type descriptor
'typestr': '<i4', # same, in another form
'strides': None, # strides; or None if in C-order
'shape': (2, 2),
'version': 3,
}
- ::
>>> from PIL import Image >>> img = Image.open('data/test.png') >>> img.__array_interface__ {'version': 3, 'data': ..., 'shape': (200, 200, 4), 'typestr': '|u1'} >>> x = np.asarray(img) >>> x.shape (200, 200, 4)
注意
还定义了数组接口的更友好的 C 版本。
2.2.4. 数组兄弟:chararray、maskedarray¶
2.2.4.1. chararray:矢量化字符串操作¶
>>> x = np.char.asarray(['a', ' bbb', ' ccc'])
>>> x
chararray(['a', ' bbb', ' ccc'], dtype='<U5')
>>> x.upper()
chararray(['A', ' BBB', ' CCC'], dtype='<U5')
2.2.4.2. masked_array:缺失数据¶
掩码数组是可以包含缺失或无效条目的数组。
例如,假设我们有一个数组,其中第四个条目无效
>>> x = np.array([1, 2, 3, -99, 5])
一种描述方法是创建一个掩码数组
>>> mx = np.ma.masked_array(x, mask=[0, 0, 0, 1, 0])
>>> mx
masked_array(data=[1, 2, 3, --, 5],
mask=[False, False, False, True, False],
fill_value=999999)
掩码均值会忽略掩码数据
>>> mx.mean()
np.float64(2.75)
>>> np.mean(mx)
np.float64(2.75)
警告
并非所有 NumPy 函数都尊重掩码,例如np.dot,因此请检查返回类型。
masked_array返回原始数组的**视图**
>>> mx[1] = 9
>>> x
array([ 1, 9, 3, -99, 5])
掩码¶
可以通过赋值修改掩码
>>> mx[1] = np.ma.masked
>>> mx
masked_array(data=[1, --, 3, --, 5],
mask=[False, True, False, True, False],
fill_value=999999)
赋值时会清除掩码
>>> mx[1] = 9
>>> mx
masked_array(data=[1, 9, 3, --, 5],
mask=[False, False, False, True, False],
fill_value=999999)
掩码也可以直接访问
>>> mx.mask
array([False, False, False, True, False])
可以使用给定值填充掩码条目以获取回常规数组
>>> x2 = mx.filled(-1)
>>> x2
array([ 1, 9, 3, -1, 5])
也可以清除掩码
>>> mx.mask = np.ma.nomask
>>> mx
masked_array(data=[1, 9, 3, -99, 5],
mask=[False, False, False, False, False],
fill_value=999999)
领域感知函数¶
掩码数组包还包含领域感知函数
>>> np.ma.log(np.array([1, 2, -1, -2, 3, -5]))
masked_array(data=[0.0, 0.693147180559..., --, --, 1.098612288668..., --],
mask=[False, False, True, True, False, True],
fill_value=1e+20)
注意
NumPy 1.7 中正在引入对处理数组中缺失数据的简化和更无缝的支持。敬请期待!
2.2.4.3. recarray:纯粹的便利性¶
>>> arr = np.array([('a', 1), ('b', 2)], dtype=[('x', 'S1'), ('y', int)])
>>> arr2 = arr.view(np.recarray)
>>> arr2.x
array([b'a', b'b'], dtype='|S1')
>>> arr2.y
array([1, 2])
2.2.5. 总结¶
ndarray 的结构:数据、dtype、步长。
通用函数:逐元素操作,如何创建新的通用函数
Ndarray 子类
用于与其他工具集成的各种缓冲区接口
最近的添加:PEP 3118、广义 ufunc
2.2.6. 为 NumPy/SciPy 做贡献¶
2.2.6.1. 为什么¶
“有 bug 吗?”
“我不理解这部分代码应该做什么?”
“我有一些很酷的代码。你想用吗?”
“我想帮忙!我能做些什么?”
2.2.6.2. 报告 bug¶
Bug 跟踪器(优先使用此方法)
邮件列表(https://numpy.com.cn/community/)
如果你不确定
如果一周左右没有回复?直接提交 bug 报告。
好的 bug 报告¶
Title: numpy.random.permutations fails for non-integer arguments
I'm trying to generate random permutations, using numpy.random.permutations
When calling numpy.random.permutation with non-integer arguments
it fails with a cryptic error message::
>>> rng.permutation(12)
array([ 2, 6, 4, 1, 8, 11, 10, 5, 9, 3, 7, 0])
>>> rng.permutation(12.) #doctest: +SKIP
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "_generator.pyx", line 4844, in numpy.random._generator.Generator.permutation
numpy.exceptions.AxisError: axis 0 is out of bounds for array of dimension 0
This also happens with long arguments, and so
np.random.permutation(X.shape[0]) where X is an array fails on 64
bit windows (where shape is a tuple of longs).
It would be great if it could cast to integer or at least raise a
proper error for non-integer types.
I'm using NumPy 1.4.1, built from the official tarball, on Windows
64 with Visual studio 2008, on Python.org 64-bit Python.
你想要做什么?
能够重现 bug 的简短代码片段(如果可能)
实际发生了什么
你期望发生什么
平台(Windows/Linux/OSX,32/64 位,x86/PPC,…)
NumPy/SciPy 版本
>>> print(np.__version__) 2...
检查以下内容是否符合预期
>>> print(np.__file__) /...
如果你有旧的/损坏的 NumPy 安装。
如果不确定,尝试删除现有的 NumPy 安装,然后重新安装…
2.2.6.3. 为文档做贡献¶
文档编辑器
注册
注册账号
订阅
scipy-dev邮件列表(仅限订阅者)邮件列表的问题:你会收到邮件
但是:你可以关闭邮件接收
“更改订阅选项”,位于以下链接底部
https://mail.python.org/mailman3/lists/scipy-dev.python.org/
发送邮件到
scipy-dev邮件列表;请求激活To: scipy-dev@scipy.org Hi, I'd like to edit NumPy/SciPy docstrings. My account is XXXXX Cheers, N. N.
检查风格指南
不要害怕;要修复一个小问题,只需修复它即可
编辑
编辑源代码并发送补丁(与 bug 报告类似)
在邮件列表中抱怨
2.2.6.4. 贡献特性¶
特性的贡献在 https://numpy.com.cn/doc/stable/dev/ 中有说明。
2.2.6.5. 如何提供帮助,一般而言¶
随时欢迎修复 bug!
什么最让你恼火
浏览跟踪器
文档工作
API 文档:改进文档字符串
熟悉某个 SciPy 模块吗?
用户指南
在沟通渠道上提问
numpy-discussion列表scipy-dev列表